AI Model Scoring Benchmark
Purpose & Methodology
GitVelocity scores every pull request on a 0-100 scale across 6 sub-categories using a large language model — Anthropic Claude by default, with OpenRouter-hosted models available as alternatives. To choose and validate the scoring model, we benchmark candidates against a fixed reference model. Opus 4.7 is that reference — the gold standard — and this page compares Sonnet 5, Opus 4.8, Opus 4.6, Sonnet 4.6, Haiku 4.5, Kimi K2.6, GLM 5.1, and Qwen3.6 Plus against it on three dimensions:
- Cost - Token usage and USD cost per review
- Accuracy - Score deviation from the Opus 4.7 reference
- Stability - Variance across independent runs per model
The original benchmark cohort scored the same 20 pull-request corpus under identical conditions in a single benchmarking pass. Most models are scored with 3 independent runs per PR; Kimi K2.6 and GLM 5.1 are additionally scored with 6 runs per PR to test whether averaging more calls stabilizes the lower-cost models. Scores come only from this benchmark — never from your production data.
Claude Sonnet 5 was evaluated later on the same corpus and rubric, in its native configuration — adaptive thinking on (the config the pinned Sonnet 5 option actually runs). It was scored with 3 runs per PR, but on the largest PRs its adaptive reasoning occasionally exhausts the output-token budget and returns no parseable score, so 9 of ~74 calls dropped out and 2 of the 20 PRs land 2 clean runs instead of 3 (58 valid runs, all 20 PRs covered). Those cells are marked 3*. We evaluated Sonnet 5 as a possible new default and kept Sonnet 4.6 — the full reasoning is in Claude Sonnet 5 — evaluated, not promoted.
Which model scores your PRs? By default, GitVelocity uses Claude Sonnet 4.6 — our recommended choice for most teams. It is the best balance of cost, speed, and scoring quality, and we prefer the Anthropic model. We evaluated the newer Sonnet 5 as a replacement and did not promote it — it matches Sonnet 4.6's accuracy but costs about 79% more per call, so Sonnet 4.6 stays the default and Sonnet 5 is a selectable pinned option (see Claude Sonnet 5 — evaluated, not promoted). Opus 4.7 is the high-accuracy reference this benchmark calibrates against — it anchors the scale, but it is not the day-to-day default. The OpenRouter models (GLM, Kimi, Qwen) are opt-in, lower-cost alternatives you can bring your own key for.
Scoring
- Total score (0-100): Composite of 6 sub-scores
- Sub-scores: Scope, Architecture, Implementation, Risk, Quality, Perf/Security
- Effort Scale Factor: Applied based on PR size
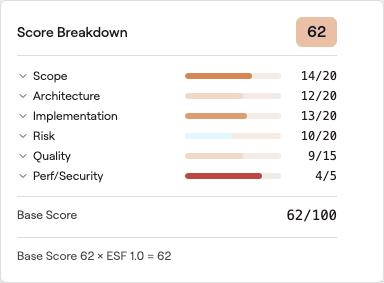 The score breakdown popover any reviewer can open on a PR. This is the model output the benchmark measures against the Opus 4.7 reference.
The score breakdown popover any reviewer can open on a PR. This is the model output the benchmark measures against the Opus 4.7 reference.
Statistical Measures
- Mean Absolute Deviation (MAD): Average
|model_avg - opus_4_7_avg|across PRs - Stability (CV): Coefficient of variation across a model's independent runs (
stddev / mean) - Estimated CV of averaged score:
raw CV / sqrt(run_count), used to estimate stability of an averaged final score - Correlation (r): Pearson correlation of per-PR average model scores vs Opus 4.7 averages
Models Under Test
| Model | Provider | Input $/1M | Output $/1M | Runs/PR | Notes |
|---|---|---|---|---|---|
claude-haiku-4-5-20251001 |
Anthropic | $1.00 | $5.00 | 3 | Fastest Anthropic model |
claude-sonnet-4-6 |
Anthropic | $3.00 | $15.00 | 3 | Mid-tier Claude — default |
claude-sonnet-5 |
Anthropic | $3.00 | $15.00 | 3* | Newest Sonnet; scored in its native adaptive-thinking-on config. Standard $3/$15 tier (intro $2/$10 through 2026-08-31). Selectable pinned option, not the default. *2 PRs have 2 clean runs. |
claude-opus-4-6 |
Anthropic | $5.00 | $25.00 | 3 | Previous-generation Opus |
claude-opus-4-7 |
Anthropic | $5.00 | $25.00 | 3 | Gold-standard reference |
claude-opus-4-8 |
Anthropic | $5.00 | $25.00 | 3 | Newest Opus |
moonshotai/kimi-k2.6 |
OpenRouter | $0.7448 | $4.655 | 6 | Candidate, reasoning disabled |
z-ai/glm-5.1 |
OpenRouter | $1.05 | $3.50 | 6 | Candidate, reasoning disabled |
qwen/qwen3.6-plus |
OpenRouter | $0.325 | $1.95 | 3 | Candidate, reasoning disabled |
Opus 4.8 uses Anthropic's published Opus standard pricing ($5/$25 per 1M), the same tier as 4.6/4.7. OpenRouter prices are from model metadata checked on 2026-04-25: Kimi K2.6, GLM 5.1, Qwen3.6 Plus.
Test Corpus
20 PRs selected for diversity across size, language, and complexity.
san-francisco (Rust) - 5 PRs
| # | PR | Lines | Files | Category |
|---|---|---|---|---|
| 1 | #537 "Ensure attio keys are properly pruned" | +1/-1 | 1 | Tiny fix |
| 2 | #548 "seed-investor-pedigree: add fields into ES" | +60/-14 | 3 | Small feature |
| 3 | #549 "seed-investor-pedigree: compute company's seed" | +314/-24 | 2 | Medium feature |
| 4 | #542 "Return structured JSON response from LLM list column API" | +138/-4 | 6 | Medium refactor |
| 5 | #545 "real time eva-list updates for people index" | +1020/-2 | 13 | Large feature |
gitvelocity (TypeScript/React/NestJS) - 5 PRs
| # | PR | Lines | Files | Category |
|---|---|---|---|---|
| 6 | #174 "Increase review processor concurrency" | +2/-2 | 2 | Tiny config |
| 7 | #169 "Add 404 not found page" | +97/-0 | 2 | Small feature |
| 8 | #175 "Add integration branch support for backfill" | +152/-54 | 9 | Medium feature |
| 9 | #176 "Add Settings > Usage page" | +923/-162 | 14 | Large feature |
| 10 | #177 "Add backfill history view with per-PR tracking" | +1447/-47 | 18 | XL feature |
gmail-integration (TypeScript) - 3 PRs
| # | PR | Lines | Files | Category |
|---|---|---|---|---|
| 11 | #257 "Protect timestamptz casts from overflow" | +36/-4 | 2 | Small fix |
| 12 | #261 "Prevent S3 orphan cleanup race condition" | +667/-111 | 10 | Large fix |
| 13 | #260 "Move backfill logic to Sidekiq background" | +436/-136 | 3 | Medium refactor |
skynet (TypeScript) - 3 PRs
| # | PR | Lines | Files | Category |
|---|---|---|---|---|
| 14 | #302 "Humanize outreach email prompt" | +18/-5 | 1 | Small prompt |
| 15 | #298 "Fix ObservationalMemory threadId crash" | +59/-12 | 2 | Small fix |
| 16 | #295 "Add interactive checkpoint tools" | +999/-5 | 18 | Large feature |
eva-web (Rails/React) - 4 PRs
| # | PR | Lines | Files | Category |
|---|---|---|---|---|
| 17 | #4364 "Fix debug page text selection" | +119/-4 | 1 | Small fix |
| 18 | #4369 "Fix ActiveRecord connection pool leaks" | +58/-37 | 6 | Medium fix |
| 19 | #4374 "Eliminate persistent MCP SSE heartbeat" | +56/-208 | 5 | Medium refactor |
| 20 | #4365 "Add get_company_people MCP tool" | +714/-1 | 4 | Large feature |
Coverage:
- Sizes: 3 tiny (<50 lines), 5 small (50-150), 6 medium (150-500), 6 large/XL (500+)
- Languages: Rust (5), TypeScript (11), Ruby/Rails (4)
- Types: features (10), fixes (6), refactors (3), config (1)
Results: Cost
Per-call cost on the same review input. Newer Opus models (4.7/4.8) are billed for noticeably more input tokens than 4.6/Sonnet/Haiku on the identical review, which drives their higher cost.
| Model | Calls | Avg Input Tokens | Avg Output Tokens | Avg Cost/Call | Total Benchmark Cost |
|---|---|---|---|---|---|
| Qwen3.6 Plus | 60 | 15,240 | 1,855 | $0.009 | $0.51 |
| Kimi K2.6 | 120 | 14,107 | 2,263 | $0.021 | $2.52 |
| GLM 5.1 | 120 | 14,163 | 1,762 | $0.021 | $2.52 |
| Haiku 4.5 | 60 | 16,788 | 2,892 | $0.031 | $1.87 |
| Sonnet 4.6 | 60 | 16,817 | 3,985 | $0.110 | $6.61 |
| Opus 4.6 | 60 | 16,788 | 1,736 | $0.127 | $7.64 |
| Opus 4.7 | 60 | 23,064 | 2,539 | $0.179 | $10.73 |
| Opus 4.8 | 60 | 23,059 | 2,840 | $0.186 | $11.18 |
| Sonnet 5 | 58 | 22,922 | 8,539 | $0.197 | $11.42 |
Qwen is the cheapest model tested, ~20x cheaper than Opus 4.7 per call. GLM and Kimi are ~8x cheaper. Sonnet 5 (thinking on) is the most expensive model tested — about $0.197 per call, ~79% more than Sonnet 4.6. Its per-token list price is the same $3/$15 as Sonnet 4.6, but two things push the per-call cost up: it uses a newer tokenizer that counts ~37% more input tokens for the same review, and its adaptive thinking emits ~8,500 output tokens per call (vs Sonnet 4.6's ~4,000). Turning thinking off brings it back to roughly $0.111 per call — about a wash with Sonnet 4.6 — but at a real accuracy cost (see below).
Results: Accuracy
Deviation from Opus 4.7 (lower is better). Per-PR model scores are the mean of each model's configured run count.
| Model | Runs/PR | Mean Total Score | MAD vs Opus 4.7 | Max Deviation | Bias | Correlation (r) |
|---|---|---|---|---|---|---|
| Opus 4.7 | 3 | 20.3 | 0 (reference) | 0.00 | 0.00 | 1.000 |
| Opus 4.8 | 3 | 23.0 | 2.75 | 16.00 | +2.65 | 0.988 |
| GLM 5.1 | 6 | 21.5 | 2.92 | 10.83 | +1.22 | 0.975 |
| Opus 4.6 | 3 | 22.0 | 3.18 | 13.33 | +1.68 | 0.966 |
| Haiku 4.5 | 3 | 24.6 | 4.70 | 15.00 | +4.27 | 0.966 |
| Sonnet 4.6 | 3 | 25.9 | 5.70 | 23.00 | +5.63 | 0.967 |
| Sonnet 5 | 3* | 25.9 | 5.90 | 20.33 | +5.60 | 0.975 |
| Kimi K2.6 | 6 | 26.1 | 5.93 | 20.50 | +5.80 | 0.979 |
| Qwen3.6 Plus | 3 | 27.4 | 7.22 | 20.00 | +7.09 | 0.988 |
Opus 4.8 tracks Opus 4.7 most closely of any model — MAD 2.75 and r=0.988 — but scores about 2.6 points higher on average (a consistent upward bias). GLM 5.1 is the strongest non-Anthropic model (MAD 2.92, the lowest bias of the lower-cost models at +1.22). Opus 4.6, Sonnet, Haiku, Kimi, and Qwen all over-score relative to 4.7, with Qwen the furthest off. A high correlation alongside a high bias (Qwen: r=0.988, bias +7.09) means a model ranks PRs much like 4.7 but on a shifted scale.
Sonnet 5 (thinking on) lands almost exactly on top of Sonnet 4.6 — same mean total score (25.9), near-identical deviation (MAD 5.90 vs 5.70) and over-scoring bias (+5.60 vs +5.63), with a slightly higher correlation to the reference (r 0.975 vs 0.967). Its real advantage shows up in stability, not accuracy (see below). Turning thinking off makes Sonnet 5 worse on every accuracy measure (MAD 6.17, r 0.937) — the accuracy comes from the thinking.
Per-PR Score Comparison
Each cell is the mean of the model's configured run count.
| PR# | Size | Lang | Opus 4.7 | Opus 4.8 | Opus 4.6 | GLM 5.1 | Kimi K2.6 | Sonnet 4.6 | Sonnet 5 | Haiku 4.5 | Qwen3.6 Plus |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | tiny | Rust | 1.0 | 1.0 | 1.0 | 1.2 | 1.0 | 1.3 | 1.0 | 1.0 | 1.0 |
| 2 | small | Rust | 9.3 | 11.3 | 10.7 | 12.0 | 11.2 | 12.0 | 11.7 | 24.3 | 14.3 |
| 3 | medium | Rust | 24.3 | 26.3 | 27.3 | 28.7 | 25.0 | 28.7 | 28.0 | 27.7 | 35.0 |
| 4 | medium | Rust | 10.3 | 14.3 | 19.7 | 14.0 | 15.0 | 13.3 | 13.3 | 14.0 | 14.3 |
| 5 | large | Rust | 51.7 | 58.7 | 54.3 | 49.2 | 58.7 | 62.0 | 66.7 | 49.3 | 63.3 |
| 6 | tiny | TS | 1.0 | 1.7 | 1.0 | 1.2 | 1.1 | 1.0 | 1.0 | 1.3 | 1.0 |
| 7 | small | TS | 6.3 | 7.0 | 5.7 | 5.8 | 8.1 | 7.7 | 7.3 | 7.7 | 7.0 |
| 8 | medium | TS | 14.7 | 14.3 | 18.3 | 16.7 | 23.8 | 20.3 | 22.7 | 20.7 | 23.0 |
| 9 | large | TS | 36.0 | 36.7 | 35.7 | 35.3 | 44.3 | 49.0 | 47.7 | 40.3 | 42.3 |
| 10 | xl | TS | 40.7 | 56.7 | 54.0 | 51.5 | 61.2 | 63.7 | 61.0 | 49.0 | 54.1 |
| 11 | small | TS | 6.0 | 6.3 | 6.0 | 7.7 | 7.0 | 6.3 | 7.3 | 7.7 | 9.3 |
| 12 | large | TS | 44.0 | 46.3 | 35.0 | 37.3 | 50.8 | 43.3 | 49.3 | 46.3 | 52.3 |
| 13 | medium | TS | 36.7 | 42.7 | 35.3 | 35.3 | 45.0 | 40.3 | 38.7 | 34.7 | 56.7 |
| 14 | tiny | TS | 3.3 | 3.0 | 3.0 | 4.2 | 2.1 | 3.7 | 3.3 | 4.3 | 2.0 |
| 15 | small | TS | 6.7 | 7.3 | 8.3 | 11.3 | 14.2 | 10.7 | 14.0 | 12.3 | 11.3 |
| 16 | large | TS | 46.0 | 50.7 | 54.7 | 45.5 | 59.3 | 66.3 | 56.0 | 55.7 | 60.0 |
| 17 | small | Ruby | 6.3 | 6.3 | 5.3 | 10.2 | 7.2 | 8.7 | 11.0 | 9.3 | 10.0 |
| 18 | medium | Ruby | 12.0 | 11.7 | 10.3 | 16.5 | 13.8 | 12.7 | 9.0 | 15.0 | 20.0 |
| 19 | medium | Ruby | 16.0 | 21.0 | 21.0 | 18.0 | 29.8 | 30.7 | 30.7 | 23.0 | 25.3 |
| 20 | large | Ruby | 34.0 | 36.0 | 33.3 | 29.2 | 43.8 | 37.3 | 38.7 | 48.0 | 45.7 |
Per-Sub-Score Accuracy (MAD vs Opus 4.7)
| Model | Scope | Architecture | Implementation | Risk | Quality | Perf/Security |
|---|---|---|---|---|---|---|
| Opus 4.8 | 0.62 | 0.65 | 0.62 | 1.02 | 0.53 | 0.25 |
| Opus 4.6 | 0.73 | 0.85 | 0.62 | 0.88 | 0.77 | 0.22 |
| GLM 5.1 | 1.82 | 1.17 | 1.02 | 1.36 | 0.50 | 0.48 |
| Sonnet 4.6 | 1.23 | 1.73 | 1.12 | 1.00 | 1.03 | 0.20 |
| Sonnet 5 | 1.90 | 1.32 | 1.04 | 1.33 | 0.75 | 0.24 |
| Kimi K2.6 | 1.39 | 1.59 | 2.08 | 1.36 | 1.06 | 0.53 |
| Haiku 4.5 | 2.10 | 1.07 | 2.55 | 1.37 | 1.48 | 0.70 |
| Qwen3.6 Plus | 2.43 | 2.28 | 2.98 | 1.93 | 1.72 | 0.73 |
Opus 4.8 and 4.6 are the tightest at the sub-score level; 4.8's largest gap is Risk (1.02). Qwen's largest gap is Implementation, where it most over-scores larger feature PRs.
Results: Stability
Coefficient of variation across each model's independent runs. Lower is better.
| Model | Runs/PR | Avg CV (total_score) | Max CV | PRs with CV > 10% | Estimated CV of Averaged Score |
|---|---|---|---|---|---|
| Sonnet 5 | 3* | 5.5% | 14.1% | 4/20 | 3.1% |
| Opus 4.7 | 3 | 6.3% | 29.8% | 3/20 | 3.7% |
| Opus 4.6 | 3 | 6.8% | 22.6% | 4/20 | 3.9% |
| Qwen3.6 Plus | 3 | 8.6% | 36.3% | 8/20 | 5.0% |
| Sonnet 4.6 | 3 | 10.0% | 35.4% | 6/20 | 5.8% |
| Opus 4.8 | 3 | 10.7% | 28.3% | 8/20 | 6.2% |
| GLM 5.1 | 6 | 15.6% | 36.3% | 13/20 | 6.4% |
| Kimi K2.6 | 6 | 16.1% | 39.8% | 16/20 | 6.6% |
| Haiku 4.5 | 3 | 19.9% | 68.8% | 15/20 | 11.5% |
Sonnet 5 (thinking on) is the most reproducible non-reference model — 5.5% average CV, even steadier than Opus 4.7's 6.3%. Its adaptive reasoning gives it unusually consistent run-to-run scores. Opus 4.7 and 4.6 are the most reproducible of the Opus models (~6-7% CV, ≤4/20 PRs above 10%). Opus 4.8 is noticeably noisier — 10.7% average CV, roughly 1.7x 4.7's run-to-run variance. Kimi and GLM are the noisiest per call (≥15.6%); averaging 6 calls narrows their averaged-score noise to roughly Sonnet's 3-run level but does not make individual calls as steady as Opus. Haiku is the least stable model overall.
Stability by PR Size
| Model | Tiny | Small | Medium | Large/XL |
|---|---|---|---|---|
| Opus 4.8 | 9.4% | 9.7% | 17.0% | 5.7% |
| Sonnet 4.6 | 16.1% | 12.9% | 10.7% | 4.1% |
| Sonnet 5 | 4.7% | 7.2% | 3.4% | 6.4% |
| Qwen3.6 Plus | 0.0% | 11.7% | 10.5% | 8.5% |
| Kimi K2.6 | 13.3% | 25.7% | 15.1% | 10.6% |
| GLM 5.1 | 26.8% | 12.8% | 15.3% | 12.5% |
| Haiku 4.5 | 15.4% | 24.5% | 24.2% | 14.0% |
Opus 4.8's instability concentrates on medium PRs (17.0% CV) — the same band where it diverges most from 4.7 — while it is steady on large PRs (5.7%). GLM's high tiny-PR CV is inflated by very small score denominators. Haiku is noisy across every size band.
Does 2x More Testing Stabilize Kimi/GLM?
First 3 runs vs the full 6-run averages for Kimi and GLM.
| Model | Runs Averaged | MAD vs Opus 4.7 | Bias | r | Avg Raw CV | Est. CV of Averaged Score | Avg Cost per Averaged PR |
|---|---|---|---|---|---|---|---|
| Kimi K2.6 | 3 | 5.81 | +5.66 | 0.976 | 13.7% | 7.9% | $0.063 |
| Kimi K2.6 | 6 | 5.93 | +5.80 | 0.979 | 16.1% | 6.6% | $0.126 |
| GLM 5.1 | 3 | 3.57 | +1.53 | 0.960 | 12.9% | 7.5% | $0.063 |
| GLM 5.1 | 6 | 2.92 | +1.22 | 0.975 | 15.6% | 6.4% | $0.126 |
Answer: averaging more calls helps GLM but not Kimi. GLM's MAD improves from 3.57 to 2.92 and its correlation from 0.960 to 0.975 with 6 runs. Kimi's MAD does not improve (5.81 → 5.93) because the extra runs do not reduce its large, consistent upward bias (+5.8). The averaged-score noise drops for both, but that does not fix a systematic bias.
Results: By Size
Accuracy (MAD vs Opus 4.7) by PR size category.
| Model | Tiny (<50) | Small (50-150) | Medium (150-500) | Large/XL (500+) |
|---|---|---|---|---|
| Opus 4.8 | 0.33 | 0.73 | 2.94 | 5.44 |
| Opus 4.6 | 0.11 | 0.93 | 4.00 | 5.78 |
| GLM 5.1 | 0.39 | 2.67 | 2.97 | 4.33 |
| Sonnet 4.6 | 0.22 | 2.13 | 5.33 | 11.78 |
| Sonnet 5 | 0.00 | 3.33 | 5.72 | 11.17 |
| Haiku 4.5 | 0.44 | 5.33 | 4.17 | 6.83 |
| Kimi K2.6 | 0.43 | 2.58 | 6.42 | 10.97 |
| Qwen3.6 Plus | 0.44 | 3.47 | 10.06 | 10.91 |
All models converge on tiny PRs. Opus 4.8 is tightest on small/medium PRs; GLM is the best non-Opus model on large/XL PRs. The bigger over-scorers (Sonnet, Kimi, Qwen) drift most on large/XL work.
Results: By Language
Accuracy (MAD vs Opus 4.7) by primary language.
| Model | Rust | TypeScript | Ruby/Rails |
|---|---|---|---|
| Opus 4.8 | 3.00 | 2.97 | 1.83 |
| Opus 4.6 | 3.27 | 3.55 | 2.08 |
| GLM 5.1 | 2.67 | 2.71 | 3.79 |
| Sonnet 4.6 | 4.13 | 6.58 | 5.25 |
| Sonnet 5 | 4.80 | 6.09 | 6.75 |
| Haiku 4.5 | 4.87 | 3.88 | 6.75 |
| Kimi K2.6 | 2.83 | 7.09 | 6.58 |
| Qwen3.6 Plus | 6.27 | 7.32 | 8.17 |
Opus 4.8 and GLM 5.1 are the most language-balanced of the non-reference models. Kimi and Sonnet drift most on TypeScript; Qwen is weakest across the board.
Opus 4.7 vs the newest model, Opus 4.8
We also evaluated Anthropic's newest release, Opus 4.8, as a scoring model. It tracks Opus 4.7's rankings almost perfectly (r=0.988, the closest of any model on this corpus), but on the same reviews it:
- scores about 2.6 points higher on average (a consistent upward bias),
- varies more between repeated runs (10.7% CV vs 4.7's 6.3% — roughly 1.7x the run-to-run variance), and
- costs the most of any model tested.
A scoring reference is most valuable when it is steady and reproducible, so Opus 4.7 remains GitVelocity's gold standard. Opus 4.8 is a strong, capable model — it simply scores a touch higher and less consistently than the reference, which is why we kept 4.7 as the anchor your scores are calibrated to.
Claude Sonnet 5 — evaluated, not promoted
When Anthropic shipped Sonnet 5, we tested it as a replacement for your default scoring model, Sonnet 4.6. The bar for promotion was simple: score at least as well as Sonnet 4.6 on this benchmark, and cost less per PR. We evaluated it in both of its configurations and it cleared neither bar cleanly, so your default stays on Sonnet 4.6. Sonnet 5 is available as a selectable pinned option, running its native adaptive-thinking-on config.
| Sonnet 5 config | MAD vs 4.7 | r | Stability (avg CV) | Cost/call | vs Sonnet 4.6 |
|---|---|---|---|---|---|
| Thinking ON (native; what the option runs) | 5.90 | 0.975 | 5.5% | $0.197 | Accuracy ≈ tie; much steadier; cost +79% |
| Thinking OFF (cost-bounded variant) | 6.17 | 0.937 | 15.4% | $0.111 | Accuracy worse; cost ≈ tied |
| Sonnet 4.6 (your default) | 5.70 | 0.967 | 10.0% | $0.110 | — |
What the numbers show:
- With thinking on, Sonnet 5 matches Sonnet 4.6 on accuracy and is steadier. Same mean and deviation (MAD 5.90 vs 5.70), a slightly higher correlation to the reference (r 0.975 vs 0.967), and 5.5% run-to-run variation — the most reproducible of any non-reference model, steadier than even Opus 4.7. Its adaptive reasoning keeps repeat scores of the same PR very close.
- It is also the most expensive model we tested: about $0.197 per call, ~79% more than Sonnet 4.6. The per-token list price is the same ($3/$15 standard, an intro $2/$10 through 2026-08-31), but a newer tokenizer counts ~37% more input tokens and adaptive thinking emits far more output, so the per-call bill is higher.
- Thinking is what buys the accuracy, and also what drives the cost. Turn it off and Sonnet 5 gets cheaper (about $0.111, a wash with Sonnet 4.6), but its accuracy drops below 4.6 and it gets much noisier (15.4% variation). No setting is both better than 4.6 and cheaper.
- On very large PRs, thinking-on Sonnet 5 occasionally truncates: its reasoning sometimes uses up the entire output budget and returns no score. 9 of ~74 calls dropped out this way, mostly on the biggest diffs. Sonnet 4.6 does not do this.
So Sonnet 5 buys stability, not better accuracy and not lower cost, and it is the priciest option for scoring — the reverse of what we wanted from an upgrade. It stays a pinned option for teams that value its reproducibility and accept the higher cost; Sonnet 4.6 remains the price-performance default.
Recommendations
Claude Sonnet 4.6 is the default and recommended model. It is the price-performance sweet spot, and we prefer the Anthropic model — it is what scores your PRs unless you opt into another model. (GLM 5.1 is cheaper and closer to the Opus 4.7 reference on this corpus, but it requires bringing your own OpenRouter key and is an opt-in alternative, not the default.)
Claude Sonnet 5 is available as a pinned option but is not the default. With thinking on (its native config) it matches Sonnet 4.6's accuracy and is the most reproducible non-reference model (5.5% variation), but it costs about 79% more per call and occasionally truncates on very large PRs; with thinking off it is cheaper but scores worse than 4.6. See Claude Sonnet 5 — evaluated, not promoted.
Opus 4.7 is the scoring reference, not the default. It is the most reproducible of the Opus models and the anchor every other model is measured against — it defines the scale Sonnet and the rest are compared to.
GLM 5.1 is the best lower-cost option. MAD 2.92, r=0.975, and the lowest bias of the lower-cost models (+1.22) with 6-run averaging — at roughly 8x lower per-call cost than Opus 4.7. The tradeoff is noisier individual calls (15.6% raw CV), so it is best used with averaging.
Kimi K2.6 over-scores (+5.80 bias) and does not improve with more runs.
Qwen3.6 Plus is the cheapest but the least accurate here — it over-scores medium and large PRs and ranks last on deviation.
Averaging lower-cost calls is worthwhile only if you use the averaged score, and only helps models without a systematic bias (GLM, not Kimi).
Cost at Scale
Single-call cost projection:
| Volume | Qwen | GLM | Kimi | Haiku | Sonnet | Opus 4.6 | Opus 4.7 | Opus 4.8 |
|---|---|---|---|---|---|---|---|---|
| 100 PRs/month | $1 | $2 | $2 | $3 | $11 | $13 | $18 | $19 |
| 1,000 PRs/month | $9 | $21 | $21 | $31 | $110 | $127 | $179 | $186 |
| 10,000 PRs/month | $85 | $210 | $210 | $312 | $1,102 | $1,273 | $1,788 | $1,863 |
Averaged-score cost projection:
| Volume | 6x GLM | 6x Kimi | 3x Sonnet |
|---|---|---|---|
| 100 PRs/month | $13 | $13 | $33 |
| 1,000 PRs/month | $126 | $126 | $331 |
| 10,000 PRs/month | $1,260 | $1,260 | $3,306 |
Lower-cost OpenRouter option (opt-in)
Our recommended default stays Claude Sonnet 4.6 — we prefer the Anthropic model, and it is what we suggest for most teams. If cost is your priority, GitVelocity also supports bring-your-own OpenRouter keys as an opt-in alternative. Both steps below happen on the same page under Settings → AI Scoring.
1. Connect your OpenRouter key in the API Keys card.
 Click Edit on the OpenRouter row to paste your key (sk-or-...). Only the last four characters are ever shown back to you.
Click Edit on the OpenRouter row to paste your key (sk-or-...). Only the last four characters are ever shown back to you.
2. Switch the scoring model to GLM 5.1 (OpenRouter) in the Model Selection card.
 PR reviews route through OpenRouter on your own key as soon as you pick GLM 5.1. The default remains Sonnet 4.6 if you don't change it.
PR reviews route through OpenRouter on your own key as soon as you pick GLM 5.1. The default remains Sonnet 4.6 if you don't change it.
| Model | r vs Opus 4.7 | MAD | Bias | Single-call cost (1k PRs) |
|---|---|---|---|---|
| GLM 5.1 | 0.975 | 2.92 | +1.22 | $21 |
| Kimi K2.6 | 0.979 | 5.93 | +5.80 | $21 |
GLM 5.1 lands closest to the Opus 4.7 gold standard of the OpenRouter options, with far lower bias than Kimi (+1.22 vs +5.80). The default model is unchanged (Latest / Claude Sonnet 4.6); GLM 5.1 is fully opt-in.
Appendix: Notes
The dataset behind this page comprises 600 scored results — the 20-PR corpus run across all eight models, with 3 runs each (6 for Kimi and GLM). To keep scoring deterministic, models are queried at temperature 0 where the model supports it; Opus 4.7 and 4.8 are queried with their default sampling. Sonnet 4.6 is given an extended-thinking budget; the OpenRouter candidates are queried with reasoning disabled. All figures on this page come from this benchmark, not from production scores.